반응형
1. Import
import pandas as pd2. DataFrame
| Columns | |||
| Index | name | salary | deptno |
| 0 | smith | 1000 | 10 |
| 1 | timo | 2000 | 20 |
| 2 | kali | 2500 | 20 |
| 3 | echo | 5000 | 30 |
df1 = pd.DataFrame({'name': ['smith', 'timo', 'kali', 'echo'],
'salary': [1000, 2000, 2500, 5000],
'deptno': [10, 20, 20, 30]})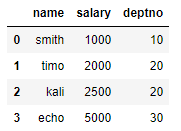
df2 = pd.DataFrame(np.arange(16).reshape(4, 4),
index = ['a', 'b', 'c', 'd'],
columns = ['red', 'blue', 'green', 'yellow'])
print(df1.columns)
print(df1.index)
'''
Index(['name', 'salary', 'deptno'], dtype='object')
RangeIndex(start=0, stop=4, step=1)
'''
3. Elements 선택
(1) Column 선택 => return 값으로 Series 가 반환된다.
* DataFrame[칼럼명]
* DataFrame.칼럼명
print(df1['name'])
'''
0 smith
1 timo
2 kali
3 echo
Name: name, dtype: object
'''
print(df1.name)
'''
0 smith
1 timo
2 kali
3 echo
Name: name, dtype: object
'''(2) Row 선택 => return 값으로 Series 가 반환된다.
* DataFrame.loc[index] <= 정수형 인덱스 외에 지정한 인덱스로 참조할 수 있다.
* DataFrame.iloc[정수 인덱스] <= 0, 1, 2, 3... 배열 인덱스 참조하듯이 사용
print(df2.loc['a'])
'''
red 0
blue 1
green 2
yellow 3
Name: a, dtype: int32
'''
print(df2.iloc[0])
'''
red 0
blue 1
green 2
yellow 3
Name: a, dtype: int32
'''(3) Element 선택
print(df2['green']['c']) # 10
4. Add & Delete Columns
* DataFrame[새로운 칼럼명] = List
df1['dept'] = ['marketing', 'management', 'computer', 'software']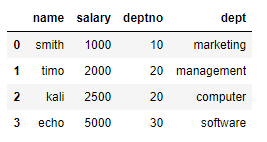
ser1 = pd.Series(np.arange(4))
df1['num'] = ser1
* del DataFrame[삭제하고 싶은 칼럼명]
del df1['num']
5. 원하는 행 찾기
(1) df1에서 salary가 2000보다 큰 행을 찾기
df1[df1.salary > 2000]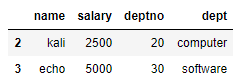
(2) df1에서 salary가 2000보다 큰 직원의 이름 찾기
df1[df1.salary > 2000].name
'''
2 kali
3 echo
Name: name, dtype: object
'''
6. Drop Elements in DataFrame
* DataFrame.drop(인덱스, (default) axis = 0): Drop Row
# Drop Row
df1.drop([0, 1])
* DataFrame.drop(컬럼명, axis = 1): Drop Column
df1.drop(['deptno', 'dept'], axis = 1)
7. Describe
* DataFrame.describe()
emp = pd.DataFrame({'num': [1, 2, 3, 4, 5],
'name': ['smith', 'kali', 'timo', 'echo', 'shco'],
'deptno': [10, 10, 20, 20, 50],
'salary': [1000, 2000, 4000, 5000, 10000]})
emp.describe()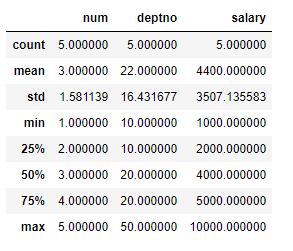
emp['salary'].describe()
반응형
'프로그래밍' 카테고리의 다른 글
| [Python] Data Manipulation (0) | 2021.05.07 |
|---|---|
| [Python] Pandas Library(Series)(2) (0) | 2021.05.06 |
| [Python] Pandas Library 활용(Series)(1) (0) | 2021.05.05 |
| [Python] NumPy Library 활용(2) (0) | 2021.05.05 |
| [Python] NumPy Library 활용(1) (0) | 2021.05.04 |