1. Import & Ready
import numpy as np
import pandas as pd
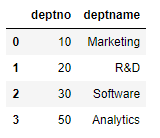
emp = pd.DataFrame({'num': [1, 2, 3, 4, 5],
'name': ['smith', 'kali', 'timo', 'echo', 'shco'],
'deptno': [10, 10, 20, 20, 50],
'salary': [1000, 2000, 4000, 5000, 10000]})
dept = pd.DataFrame({'deptno': [10, 20, 30, 50],
'deptname': ['Marketing', 'R&D', 'Software', 'Analytics']}) |
 |
2. Merge
* pd.merge(DataFrame1, DataFrame2, on = 칼럼명)
* pd.merge(DataFrame1, DataFrame2, left_on = DataFrame1의 칼럼명, right_on = DataFrame2의 칼럼명)
pd.merge(emp, dept, on='deptno')
pd.merge(emp, dept, left_on = 'deptno', right_on = 'deptno')
# left_on의 deptno는 emp의 deptno
# right_on의 deptno는 dept의 deptno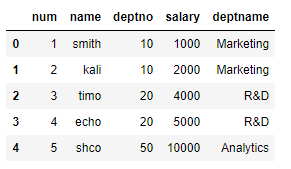
* pd.merge(DataFrame1, DataFrame2, on = 칼럼명, how = 조인방법(outer, left, right))
pd.merge(emp, dept, on='deptno', how='outer')
* DataFrame1.join(DataFrame2)
emp.join(dept)
# ValueError: columns overlap but no suffix specified: Index(['deptno'], dtype='object')
"ValueError: columns overlap but no suffix specified: Index(['deptno'], dtype='object')"
'deptno'가 중복되기 때문에 에러 발생!
* DataFrame1.join(DataFrame2, lsuffix = DataFrame1 중복 칼럼 구분명, rsuffix = DataFrame2 중복 칼럼 구분명)
emp.join(dept, lsuffix = '_emp', rsuffix = '_dept')
3. Stack, Unstack
idx = {0: 'zero', 1: 'first', 2: 'second', 3: 'third', 4: 'fourth'}
emp.rename(index = idx, inplace = True)
* DataFrame.stack(): 컬럼들이 행으로 가면서 피벗테이블처럼 변환(Like 계층구조)
emp.stack()
'''
zero num 1
name smith
deptno 10
salary 1000
first num 2
name kali
deptno 10
salary 2000
second num 3
name timo
deptno 20
salary 4000
third num 4
name echo
deptno 20
salary 5000
fourth num 5
name shco
deptno 50
salary 10000
dtype: object
'''
* Series.unstack(): Series -> Dataframe으로 변환
tmp_ser = emp.stack()
tmp_ser.unstack()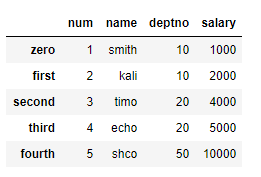
4. Mapping
map = {
'label1' : 'value1',
'label2' : 'value2',
...
}새롭게 적용할 내용을 딕셔너리 자료구조를 활용해 작성하여 Replace 함수를 이용하여 매핑한다.
* DataFrame1.replace(new dictionary)
new_name = {'smith': 'new_smith',
'kali': 'new_kali',
'timo': 'new_timo',
'echo': 'new_echo',
'shco': 'new_scho'}
emp.replace(new_name)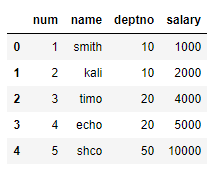 [변환 전] |
 [변환 후] |
응용) Series의 NaN 값을 대체할 수 있다.
ser_tmp = pd.Series([np.nan, np.nan])
'''
0 NaN
1 NaN
dtype: float64
'''
ser_tmp.replace(np.nan, 0)
'''
0 0.0
1 0.0
dtype: float64
'''
* DataFrame1.map(new Dictionary): 각 key에 대응되는 value 매핑해주는 함수
hobby = {'smith': 'game',
'kali': 'sports',
'timo': 'music',
'echo': 'game',
'shco': 'study'}
emp['hobby'] = emp['name'].map(hobby) [Mapping 이전] |
 [Mapping 이후] |
5. Discretization, Binning
* Pandas.cut(new Array, new bin): 배열을 bin의 범위로 나누기. 예를 참고해야 이해가 빠를 것 같다.
research_results = np.random.randint(0, 100, 16)
# 조사 결과: 0 ~ 100 사이의 난수 16개를 생성
'''
array([50, 44, 66, 13, 74, 28, 37, 96, 18, 25, 25, 81, 31, 47, 9, 24])
'''
bins = [0, 25, 50, 75, 100]
# 범위
belong = pd.cut(research_results, bins)
# 조사 결과가 어느 범위에 속하는지 cut 함수를 사용해 알아보자
'''
[(25, 50], (25, 50], (50, 75], (0, 25], (50, 75], ..., (75, 100], (25, 50], (25, 50], (0, 25], (0, 25]]
Length: 16
Categories (4, interval[int64]): [(0, 25] < (25, 50] < (50, 75] < (75, 100]]
'''=> pd.cut으로 나오는 결과물의 Type: Categorical
type(belong)
# pandas.core.arrays.categorical.Categorical
* Categorical.categories: Categorical의 카테고리 범주
* Categorical.codes: Categorical의 카테고리 범주에 속하는 결과. categories의 인덱스로 결과가 나온다.
belong.categories
'''
IntervalIndex([(0, 25], (25, 50], (50, 75], (75, 100]],
closed='right',
dtype='interval[int64]')
'''
belong.codes
'''
array([1, 1, 2, 0, 2, 1, 1, 3, 0, 0, 0, 3, 1, 1, 0, 0], dtype=int8)
'''* Pandas.value_counts(Categorical): 각 범주별로 속한 원소 갯수 => return Series
pd.value_counts(belong)
'''
(25, 50] 6
(0, 25] 6
(75, 100] 2
(50, 75] 2
dtype: int64
'''
IF) 범위를 알지 못하고, 범위를 x개로 나누어야 할 때는?
* Pandas.qcut(new Array, x): x개의 범위로 구분
unknown_bin = pd.qcut(research_results, 5)
'''
[(44.0, 66.0], (28.0, 44.0], (44.0, 66.0], (8.999, 24.0], (66.0, 96.0],
..., (66.0, 96.0], (28.0, 44.0], (44.0, 66.0], (8.999, 24.0], (8.999, 24.0]]
Length: 16
Categories (5, interval[float64]):
[(8.999, 24.0] < (24.0, 28.0] < (28.0, 44.0] < (44.0, 66.0] < (66.0, 96.0]]
'''unknown_bin.value_counts()
'''
(8.999, 24.0] 4
(24.0, 28.0] 3
(28.0, 44.0] 3
(44.0, 66.0] 3
(66.0, 96.0] 3
dtype: int64
'''
6. Permutation
* Permutation: 순서가 부여된 임의의 집합을 다른 순서로 뒤섞는 연산
random_frame = pd.DataFrame(np.arange(25).reshape(5, 5))
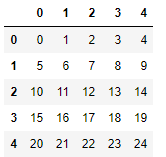
new_order = np.random.permutation(5) # index의 순서를 뒤섞음
'''
array([0, 3, 2, 1, 4])
'''
random_frame.take(new_order) # 뒤섞인 index의 순서를 적용

또 다른 예시
df = pd.DataFrame(np.arange(99, -1, -1).reshape(10, -1))
# 행 순서 무작위 변경
df = df.loc[np.random.permutation(10)] 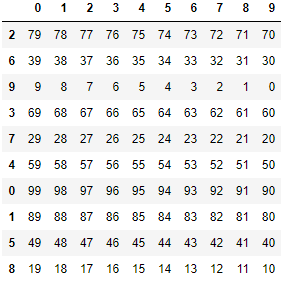
# 컬럼 순서 무작위 변경
df = df[np.random.permutation(10)] 
'프로그래밍' 카테고리의 다른 글
| [Python] Matplotlib 활용(1) (0) | 2021.05.09 |
|---|---|
| [Python] Data Aggregation (0) | 2021.05.09 |
| [Python] Pandas Library(Series)(2) (0) | 2021.05.06 |
| [Python] Pandas Library 활용(DataFrame) (0) | 2021.05.06 |
| [Python] Pandas Library 활용(Series)(1) (0) | 2021.05.05 |