반응형
※ 3행 3열의 정수 행렬을 생성하고, pandas DataFrame으로 로드한다.
import pandas as pd
import numpy as np
matrix = pd.DataFrame(np.random.randint(0, 100, size = (3, 3)), columns = ['a', 'b', 'c'])
matrix
※ pandas DataFrame을 다시 spark.DataFrame으로 변환하여 example.csv로 저장한다.
sdf = spark.createDataFrame(matrix)
sdf.show()
sdf.toPandas().to_csv('C:\\labs\\random.csv', sep=',', index=False)※ example.csv 파일을 읽어서 spark DataFrame으로 로드하고 컬럼들의 sum, avg, corr 표시
import findspark
findspark.init()
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
new_sdf = spark.read.csv('C:\\labs\\random.csv', header = True, inferSchema = True)
new_sdf.show()
new_sdf.createOrReplaceTempView('table1')
spark.sql('select sum(a), sum(b), sum(c) from table1 ').show()
spark.sql('select avg(a), avg(b), avg(c) from table1 ').show()
print('a&b corr: ', new_sdf.corr('a', 'b'))
print('b&c corr: ', new_sdf.corr('b', 'c'))
print('a&c corr: ', new_sdf.corr('a', 'c'))
※ score.csv파일을 불러와 Speed 컬럼을 추가(20m 기준 swimInSeconds 시간만큼 진행)
import findspark
findspark.init()
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
score_sdf = spark.read.csv('C:\\labs\\score.csv', header = True, inferSchema = True)
# option으로 inferSchema = True를 넣어주면 자동으로 타입을 찾아서 스키마를 구성한다.
score_sdf.show()
score_sdf.printSchema()
score_sdf = score_sdf.withColumn('Speed', 20.0/score_sdf['swimInSeconds'])
score_sdf.printSchema()
score_sdf.show()
* round 함수를 Import해서 사용(1)
from pyspark.sql.functions import round
score_sdf.createOrReplaceTempView('adapt_round')
spark.sql('Select id, gender, job, swimInSeconds, round(Speed, 3) from adapt_round').show()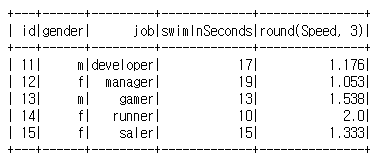
* round 함수를 Import해서 사용(2)
# 또는
score_sdf = score_sdf.withColumn('Speed', round(20.0/score_sdf['swimInSeconds'], 3))
score_sdf.show()
반응형
'프로그래밍' 카테고리의 다른 글
| [데이터 수집] 빅데이터 수집 시스템 개발(BeautifulSoup) (0) | 2021.06.15 |
|---|---|
| [pyspark] pyspark 프로그래밍 예제2 (0) | 2021.06.11 |
| [Window Spark] Window OS에 Spark 설치 (0) | 2021.06.10 |
| [Spark] Ubuntu 20.04 Spark (0) | 2021.06.09 |
| [Sqoop] Ubuntu 20.04 Sqoop 활용(2) - 예시 (0) | 2021.06.08 |