반응형
※ Selenium
- 웹 브라우저를 실행하여 조종하는 방식을 사용
- Web Driver: 각 웹 브라우저를 조종하기 위한 드라이버 사용
- Python Code => Web Driver => Web Browser
- 사용하기 이전 준비: Selenium 설치 & Web Driver 다운로드
* Import
from bs4 import BeautifulSoup
from selenium import webdriver
import requests
* selenium's webdriver 활용 예제
driver = webdriver.Chrome('./chromedriver')
driver.implicitly_wait(1)
driver.get('http://www.kyobobook.co.kr/index.laf')
driver.implicitly_wait(1)
* 코드를 작성해 검색창에 키워드를 입력하고 검색하기
# 키워드 검색
# 키워드 입력하는 창
searchbox = driver.find_element_by_xpath('//*[@id = "searchKeyword"]')
# 버튼
searchbutton = driver.find_element_by_xpath('//*[@id = "searchTop"]/div/input')
# 검색창에 검색어를 입력하고 검색 버튼 클릭
driver.implicitly_wait(1)
searchbox.send_keys('python') # 입력할 내용
searchbutton.click()
driver.implicitly_wait(3)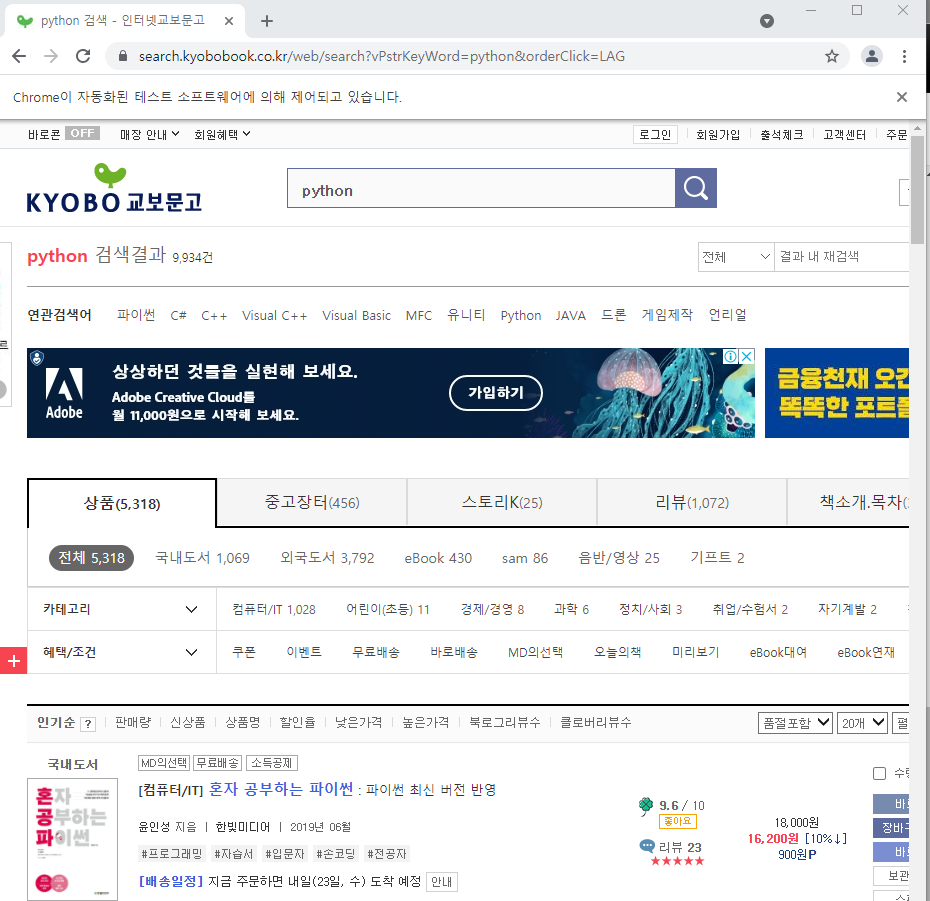
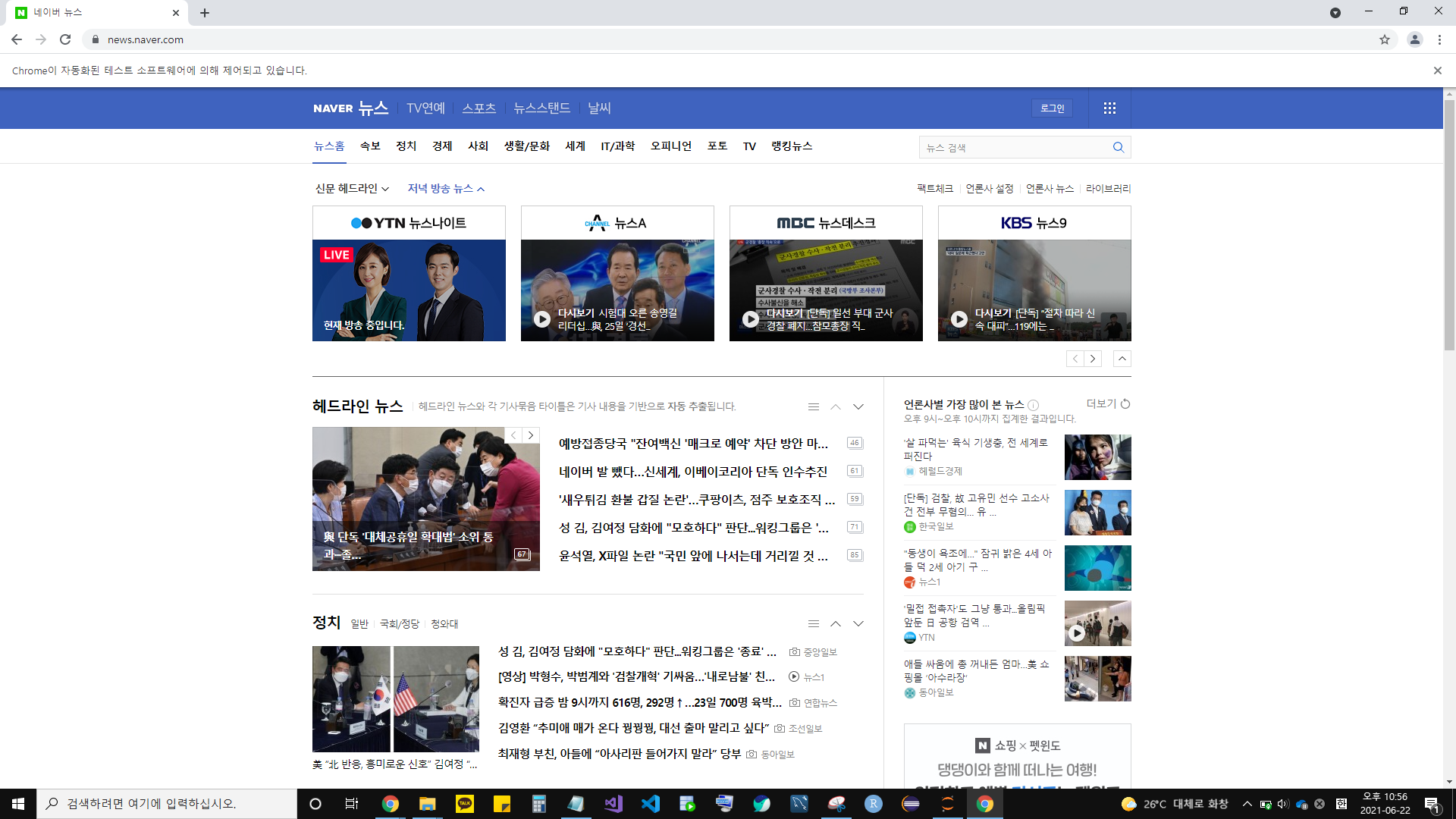
* BeautifulSoup와 Selenium을 사용해 '언론사별 가장 많이 본 뉴스' 중 1위 뉴스를 검색
driver = webdriver.Chrome('./chromedriver')
driver.implicitly_wait(1)
driver.get('http://naver.com')
driver.implicitly_wait(1)
naver_text = BeautifulSoup(driver.page_source, 'html.parser')
news_url = ''
for i in naver_text.find_all(class_ = 'nav'):
if i['data-clk'] == 'svc.news':
news_url = i['href']news_text = requests.get(news_url).text
n_text = BeautifulSoup(news_text, 'html.parser')
n_text.find('a', class_="list_tit nclicks('rig.renws2')").text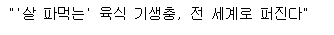
* Selenium만을 사용해 '언론사별 가장 많이 본 뉴스' 중 1위 뉴스를 검색
driver = webdriver.Chrome('./chromedriver')
driver.implicitly_wait(1)
driver.get('http://naver.com')
driver.implicitly_wait(1)
# Selenium만 사용
news_link = driver.find_element_by_xpath('//*[@id="NM_FAVORITE"]/div/ul[2]/li[2]/a')
news_link.click()
driver.implicitly_wait(2)
top_news = driver.find_element_by_xpath('//*[@id="_rankingList0"]/li[1]/div/div/div/a')
top_news.text결과는 위와 동일
* 교보문고에서 'python' 키워드로 검색하여 1~10 페이지까지 첫 아이템 제목 표시하기
import time
driver = webdriver.Chrome('./chromedriver')
driver.implicitly_wait(1)
driver.get('http://www.kyobobook.co.kr/index.laf')
driver.implicitly_wait(1)
# 키워드 검색
# 키워드 입력하는 창
searchbox = driver.find_element_by_xpath('//*[@id = "searchKeyword"]')
# 버튼
searchbutton = driver.find_element_by_xpath('//*[@id = "searchTop"]/div/input')코드를 이어서 실행할 경우 오류가 발생한다. 참조하기 전 위치를 찾으려고 하다보니 오류가 발생하는 것으로 생각한다.
# 검색창에 검색어를 입력하고 검색 버튼 클릭
driver.implicitly_wait(1)
searchbox.send_keys('python') # 입력할 내용
searchbutton.click()
driver.implicitly_wait(3)
li = []
for i in range(0, 10):
# list에서 첫 번째 아이템 제목 추출
book_title = driver.find_element_by_xpath('//*[@class = "list_search_result"]/form/table/tbody/tr/td[2]/div[2]/a/strong').text
li.append(book_title)
time.sleep(2)
# 다음 페이지로 이동
button_next = driver.find_element_by_xpath('//*[@class = "list_button_wrap"]/div/a[3]')
button_next.click()
time.sleep(2)
* naver => '책'이동 => '인공지능' 검색 => 책 10권 목차를 파일에 이어쓰기
(페이지 이동: Selenium / 데이터 추출: BeautifulSoup 을 사용하여 제작)
from bs4 import BeautifulSoup
from selenium import webdriver
import requests
import time
driver = webdriver.Chrome('./chromedriver')
driver.implicitly_wait(1)
driver.get('http://www.naver.com')
driver.implicitly_wait(1)
book_button = driver.find_element_by_xpath('//*[@id = "gnb"]/div/div/ul[2]/li[7]')
book_button.click()
time.sleep(2)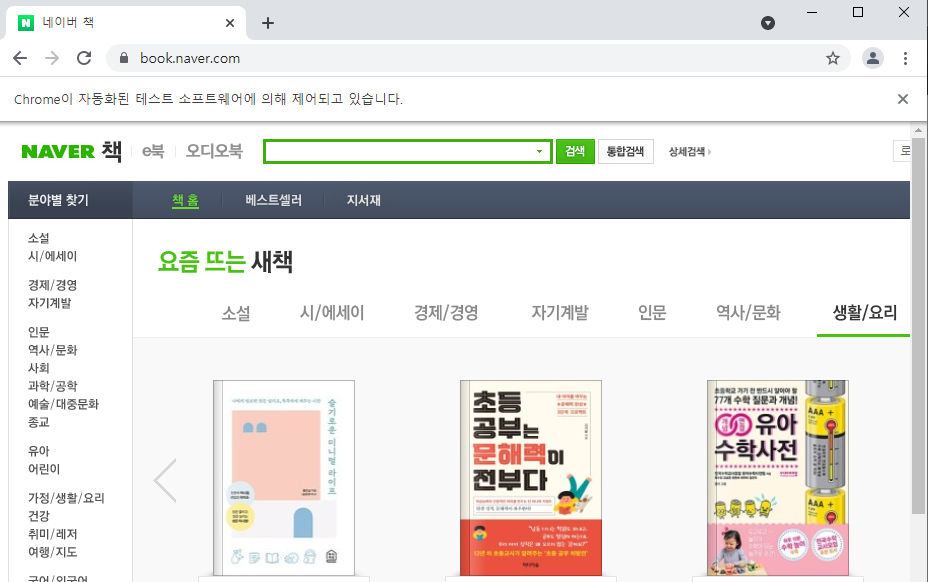
searchbox = driver.find_element_by_xpath('//*[@class = "snb_search_box"]/div/input[4]')
searchbox.send_keys('인공지능')
searchbutton = driver.find_element_by_xpath('//*[@id = "search_btn"]')
searchbutton.click()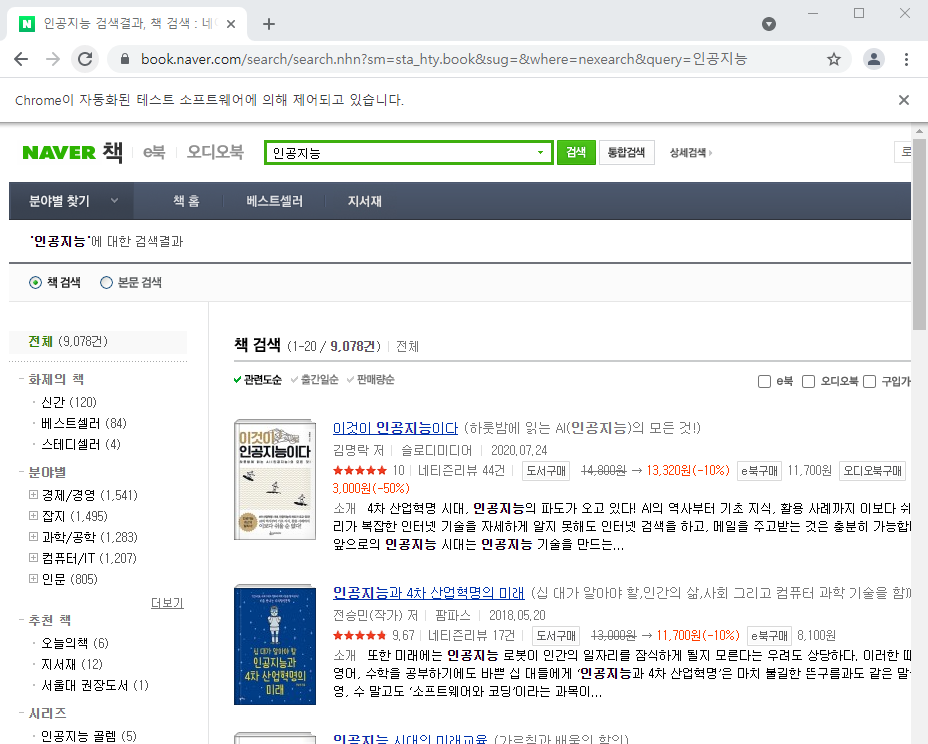
url_list = []
for i in range(1, 11):
tmp_book = driver.find_element_by_xpath(f'//*[@id = "searchBiblioList"]/li[{i}]/dl/dt/a')
url_list.append(tmp_book.get_attribute("href"))
url_list
[특이사항] 첫 번째 url에 접속하면 사이트는 정상적으로 뜨지만, 코드를 통해 htnl을 읽어오면 요청하신 페이지를 찾을 수 없습니다라는 페이지를 읽는다.
book_text = requests.get(url_list[0]).text
contents = BeautifulSoup(book_text, 'html.parser')
contents
그래서 0번 인덱스를 무시하고 html을 읽어와 파일을 만들었다.
with open('indexContents.txt', 'w') as f:
for i in range(1, 9):
book_text = requests.get(url_list[i]).text
contents = BeautifulSoup(book_text, 'html.parser')
f.write(contents.find(id = "tableOfContentsContent").text) [또 다른 방법] 아래 코드를 통해 실행하면 정상적으로 실행된다.
with open('indexContents2.txt', 'w') as f:
for url in url_list:
driver.get(url)
driver.implicitly_wait(5)
soup = BeautifulSoup(driver.page_source, 'html.parser')
cont = soup.find(id = "tableOfContentsContent")
f.write(cont.text)[Jupyter Notebook Prompt 창 에러 발생]
driver = webdriver.Chrome('./chromedriver')
driver.implicitly_wait(1)
driver.get('http://www.kyobobook.co.kr/index.laf')
driver.implicitly_wait(1)위 코드를 실행하면 아래의 에러가 프롬프트 창에 출력된다.
[ERROR: device_evnet_log_impl.cc(214)]USB: usb_device_handle_win.cc: 1058 Failed to read descriptor from node connection: 시스템에 부착된 장치가 작동하지 않습니다.
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-logging"])
driver = webdriver.Chrome('./chromedriver', options=options)
driver.implicitly_wait(1)
driver.get('http://www.kyobobook.co.kr/index.laf')
driver.implicitly_wait(1)option.add_experimental_option을 추가해 실행하면 오류가 발생하지 않는다.
반응형
'프로그래밍' 카테고리의 다른 글
| [웹] JSP 예제(MySQL과 연동, 웹 브라우저 출력)(3) (0) | 2021.06.23 |
|---|---|
| [웹] JSP 예제(MySQL과 연동, 웹 브라우저 출력)(2) (0) | 2021.06.23 |
| [R] 데이터 시각화 정의(XAMPP 다운로드, 시각화 예제, 자료 수집) (0) | 2021.06.22 |
| [웹] JSP 예제(MySQL과 연동, 웹 브라우저 출력)(1) (0) | 2021.06.22 |
| [HTML] jQuery, AJAX 활용 (0) | 2021.06.21 |