1. 컨퓨전 매트릭스의 개념
1) 컨퓨전 매트릭스(Confusion Matrix, 혼동 행렬)
- 머신러닝 혹은 통계학적 방법이 사용된 분류 모델에서, 알고리즘의 성능을 보기 쉽게 시각화하는 테이블 형태의 레이아웃
- 타당성 검증: 모델을 만들 때 모델이 얼마나 정확한 결과를 계산하는지 객관적으로 측정하는 것
2) ROC 곡선(Receiver Operating Characteristic curve)
- 특정 진단 방법의 민감도와 특이도가 어떤 관계를 갖고 있는지를 표현한 그래프
- 데이터의 정답 결과 세트를 제작 -> 데이터의 식별 결과 세트 제작 -> 2*2 컨퓨전 매트릭스 제작
3) 컨퓨전 매트릭스 형태
| 컴퓨전 매트릭스 (Confusion Matrix) |
실제(True Condition) | ||
| Positive | Negative | ||
| 예측(Predicted) | Positive(1) | True Positive (민감도) |
False Positive |
| Negative(0) | False Negative | True Negative (특이도) |
|
* True: 실제와 예측이 일치하는 경우
* False: 실제와 예측이 일치하지 않는 경우
- 예: 진단검사의학, 예방의학에서 사용되는 표
- 민감도: 어떤 진단법을 사용했을 때 실제로 이에 해당하는 사람들을 얼마나 잘 찾아내는가 하는 기준
- 특이도: 어떤 진단법을 사용했을 때 실제로 이에 해당되지 않는 사람들을 얼마나 잘 분류하는가 하는 기준
4) 주요 성능 지표
| 용어 | 산출식 | 설명 | 예 |
| Accuracy | (TP+TN)/(TP+TN+FP+FN) | 탐지율, 정확도 (맞게 검출한 비율) |
실제 악성/정상인지 맞게 에측한 비율 |
| Precision | Tp/(TP+FP) | 정밀도 (P로 검출한 것 중 실제 P의 비율) |
악성으로 예측한 것 중 실제 악성인 샘플의 비율 |
| Recall | TP/(TP+FN) | 재현율 (실제 P를 P로 예측한 비율) |
실제 악성 샘플 중 악성으로 예측한 비율 |
| False Alarm (Fall-out) |
FP/(FP+TN) | 오검출율 (실제 N을 P로 예측한 비율) |
실제 정상 샘플을 악성으로 예측한 비율 |
| 용어 | 산출식 | 설명 | 예 |
| TPR (True Positive Rate) = Recall |
TP/(TP+FN) | 예측과 실제 모두 P | 실제 악성 샘플을 악성으로 예측한 비율 |
| TNR (True Negative Rate) |
TN/(TN+FP) | 예측과 실제 모두 N | 실제 정상 샘플을 정상으로 에측한 비율 |
| FPR (False Positive Rate) = False Alarm |
FP/(FP+TN) | 실제 N인데 P로 검출 | 실제 정상 샘플을 악성으로 예측한 비율 |
| FNR (False Negative Rate) |
FN/(TP+FN) | 실제 P인데 N으로 검출 | 실제 악성 샘플을 정상으로 예측한 비율 |
- 민감도: 1인 케이스에 대해 1이라고 예측한 것
- 특이도: 0인 케이스에 대해 0이라고 예측한 것
- 정확도(Accuracy): 전체 중에서 올바르게 예측한 정도, TP(True Positive)와 TN(True Negative)을 더하여, 전체의 합계로 나눈 값
- 정밀도(Precision): 예측한 데이터가 실제와 얼마나 적합한지를 표현한 비율, 양성인 것으로 예측된 샘플에서, 실제로 양성인 샘플의 비율, 적합율
- 민감도: 실제 양성의 수에서 예측 양성이 어느 정도 적합했는가를 보는 비율, 실제 양성인 샘플에서 양성이라고 판정된 샘플의 비율(검출률(Recall), 감도(Sensitivity), 히트율(Hit Rate), 재현률 등)
- 특이도: 실제에는 음성인 샘플에서, 음성인 것으로 판정된 샘플의 비율
- 위음성율(False Negative Rate): 실제로는 양성인 샘플에서, 음성으로 판정된 샘플의 비율
- 위양성률(False Positive Rate): 실제에는 음성인 샘플에서, 양성으로 판정된 샘플의 비율
2. 컨퓨전 매트릭스의 이용
* (예시) 스팸 메일 여부 분류 모델 컨퓨전 매트릭스
메일이 왔을 때, 스팸 메일인지 아닌지를 분류하는 모델에서 스팸 메일인 경우는 1로 일반 메일은 0으로 표현했을 때, 상태에 따른 예측값과 실제값 구하기
| 데이터 | 실제값 | 예측값 | 상태 |
| A | ? <- ( 1 ) | 0 | FN |
| B | 0 | ? <- ( 1 ) | FP |
| C | ? <- ( 0 ) | ? <- ( 0 ) | TN |
| D | 1 | ? <- ( 0 ) | FN |
| E | ? <-( 1 ) | 1 | TP |
| F | 0 | 1 | ? <- (FP) |
* 진단의 정확도는 ROC curve 아래의 면적(AUC: Area Under the ROC Curve)에 의해 측정됨
- 면적이 1인 경우: 완벽한 진단 검사
- 면적이 0.5인 경우: 쓸모 없는 검사
3. R을 이용한 컨퓨전 매트릭스 분류 모델 성능 평가
# R제공 데이터 iris 이용, iris 데이터 10개 추출
head(iris, 10)
# iris 데이터 특성치 확인
summary(iris)
* Import
# 분류와 컨퓨전 매트릭스 수행
install.packages('party')
install.packages('caret')
install.packages('e1071')
library(party) # 의사결정나무 시행
library(caret) # 교차분석 패키지
library(e1071) # 컨퓨전 매트릭스 패키지
* data 구분
# sample data
sp = sample(2, nrow(iris), replace = TRUE, prob=c(0.7, 0.3))
# 70%, 30% 학습 데이터와 테스트 데이터 set 생성
trainData = iris[sp==1, ]
testData = iris[sp==2, ]
* 분류 알고리즘 생성
# 크기와 종에 따른 분류 알고리즘 생성
myFomula = Species~Sepal.Length+Sepal.Width+Petal.Length+Petal.Width
# 알고리즘을 이용한 학습 데이터 셋 ctree(분류나무) 생성
iris_ctree = ctree(myFomula, data = trainData)
iris_ctree
* 컨퓨전 매트릭스 생성
# 예측 정도와 학습 데이터 셋의 컨퓨전 매트릭스 생성
table(predict(iris_ctree), trainData$Species)
# 컨퓨전 매트릭스 함수를 이용한 혼동행렬 생성
confusionMatrix(predict(iris_ctree), trainData$Species)

# ctree 도표 생성
plot(iris_ctree)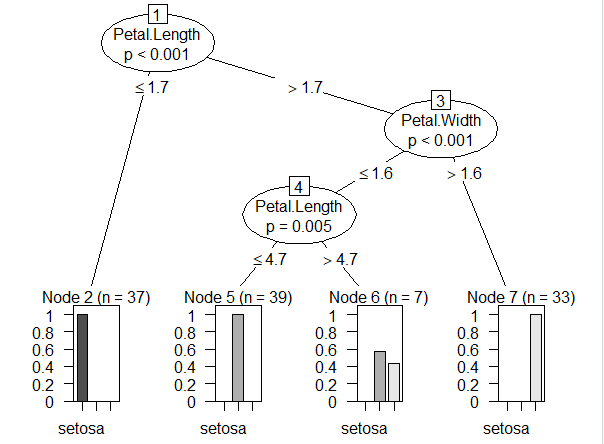
* Test Data 적용
# 테스트셋 데이터 예측분류 모델
testPred = predict(iris_ctree, newdata = testData)
# 테스트셋 분류 데이터 컨퓨전 매트릭스
table(testPred, testData$Species)
# 컨퓨전 매트릭스 생성 함수 이용
confusionMatrix(testPred, testData$Species)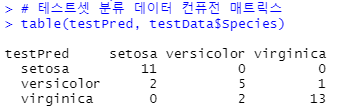

'프로그래밍' 카테고리의 다른 글
| [R] 내부 평가를 이용한 분류 모델 성능 평가 (0) | 2021.06.05 |
|---|---|
| [R] ROC 곡선 기법을 통한 분류 모델 성능 평가 (0) | 2021.06.05 |
| [R] 교차 유효성 검사를 통한 예측 모델 성능 평가 (0) | 2021.06.05 |
| [Hive] MySQL 설치 - Hive 연동 (0) | 2021.06.04 |
| [R] 예측 오차를 통한 예측 모델 성능 평가 (0) | 2021.06.02 |